
DailyDataset (GCS)#
Historical Note#
When we started building the OP Labs data platform we were heavy BigQuery users. For our most important dashboards we still are. To make it easier to migrate from BigQuery to ClickHouse we used GCS as the landing spot for ingested data. Data in GCS can be read from BigQuery by using external tables and from ClickHouse by using the s3 Table Function.
The DailyDataset data ingestion pattern was created with GCS in mind, and so all of the data
ingested using this pattern lands in GCS. If you are thinking of integrating a new data source
I strongly recommend you use the ClickHouseDataset pattern instead.
Subclassing the DailyDataset class#
Let’s take the defillama source as an example. For this datasource the data access class is
defined in the src/op_analytics/datasources/defillama/dataaccess.py directory. At the time
of writing here is how this file looks like:
from op_analytics.coreutils.partitioned.dailydata import DailyDataset
class DefiLlama(DailyDataset):
"""Supported defillama datasets."""
# Chain TVL
CHAINS_METADATA = "chains_metadata_v1"
HISTORICAL_CHAIN_TVL = "historical_chain_tvl_v1"
# Protocol TVL
PROTOCOLS_METADATA = "protocols_metadata_v1"
PROTOCOLS_TVL = "protocols_tvl_v1"
PROTOCOLS_TOKEN_TVL = "protocols_token_tvl_v1"
# Enrichment:
PROTOCOL_TVL_FLOWS_FILTERED = "tvl_flows_breakdown_filtered_v1"
# Stablecoins TVL
STABLECOINS_METADATA = "stablecoins_metadata_v1"
STABLECOINS_BALANCE = "stablecoins_balances_v1"
# DEX Volumes, Fees, and Revenue at chain and chain/name levels of granularity
VOLUME_FEES_REVENUE = "volume_fees_revenue_v1"
VOLUME_FEES_REVENUE_BREAKDOWN = "volume_fees_revenue_breakdown_v1"
# Yield
YIELD_POOLS_METADATA = "yield_pools_metadata_v1"
YIELD_POOLS_HISTORICAL = "yield_pools_historical_v1"
# Lend/Borrow
LEND_BORROW_POOLS_METADATA = "lend_borrow_pools_metadata_v1"
LEND_BORROW_POOLS_HISTORICAL = "lend_borrow_pools_historical_v1"
# Protocols metadata obtained from "dexs/dailyVolume", and "fees/dailyFees"
# and "fees/dailyRevenue" endpoints.
VOLUME_PROTOCOLS_METADATA = "volume_protocols_metadata_v1"
FEES_PROTOCOLS_METADATA = "fees_protocols_metadata_v1"
REVENUE_PROTOCOLS_METADATA = "revenue_protocols_metadata_v1"
# Token Mappings
TOKEN_MAPPINGS = "dim_token_mappings_v1"
PROTOCOL_CATEGORY_MAPPINGS = "dim_protocol_category_mappings_v1"
The DailyDataset class is an Enum and the body of the subclass are the enumeration members
which are strings. Each of these strings corresponds to the name of a table where ingested data
will be written to.
Discoverability#
The reason we require a datasource/<name>/dataaccess.py module for each datasource and an enumeration
of the associated tables is discoverability. If someone wants to know what tables are ingested for
a given datasource they can easily find it in that file.
Writing Data#
The DailyDataset class is a simple enum but it offers a number of built-in methods that help
implement data ingestion. The most important one is the write() method.
When ingesting data the mechanism of obtaining and transforming the data will be specific to each
data source. The custom code needs to figure out a way to produce a polars dataframe with the
data and then call the write() method of the destination table, for example
# Write stablecoin balances.
DefiLlama.STABLECOINS_BALANCE.write(
dataframe=most_recent_dates(result.balances_df, n_dates=BALANCES_TABLE_LAST_N_DAYS),
sort_by=["symbol", "chain"],
)
The only expectation is that the dataframe you pass to the write() method must have a dt
column, since all data in GCS is written out partitioned by dt.
Root Paths#
The name of the DailyDataset subclass and the table enum member string value will be
combined by the system to determine the root_path and in turn the exact location in GCS
where the data will be written.
For example, the class DefiLlama(DailyDataset) above has a member called
STABLECOINS_BALANCE = "stablecoins_balances_v1". The root path for this will be
defillama/stablecoins_balances_v1 and the full URI for a parquet file corresponding to
dt=2025-04-01 will be:
gs://oplabs-tools-data-sink/defillama/stablecoins_balances_v1/dt=2024-01-01/out.parquet
Other built-in functionality#
There are a number of other methods that come as part of the DailyDataset class. Refer to the
code in dailydata.py for more details.
Execution and Scheduling#
To execute the ingestion we adopted the convention of having one or more execute.py files inside
the datasource directory. Depending on the complexity of the datasource, you can have one single
execute.py at the top, or event some sub-directories each with their own execute.py files
where ingestion of a subset of tables in the data source is handled.
Using the defillama stablecoins data as an example, we have a file called
src/op_analytics/datasources/defillama/stablecoins/execute.py.
For scheduling we use Dagster assets which are then scheduled to run daily in our Dagster defs.py
file. Below we show the Dagster assent definition for the stablecoins data pull. Note how
we include creation of BigQuery external tables there, which is easy thanks to built-in functionality
in the DailyDatset class . We don’t need to recreate the external table every time the job runs,
but it helps to have that code there so that people can be aware of where the external table
definition is coming from.
@asset
def stablecoins(context: AssetExecutionContext):
"""Pull stablecoin data."""
from op_analytics.datasources.defillama.stablecoins import execute
from op_analytics.datasources.defillama.dataaccess import DefiLlama
result = execute.execute_pull()
context.log.info(result)
DefiLlama.STABLECOINS_METADATA.create_bigquery_external_table()
DefiLlama.STABLECOINS_METADATA.create_bigquery_external_table_at_latest_dt()
DefiLlama.STABLECOINS_BALANCE.create_bigquery_external_table()
Prototyping and Debugging#
To prototype we use IPython notebooks. In the notebooks we exercise the execute_pull functions
or some helper functions defined for a specific datasource. For some examples refer to the
notebooks/adhoc/defillama/ directory where we have some notebooks that were used to prototype
the original implementation of defillama pulls and are used regularly to debug issues observed
in production.
Monitoring#
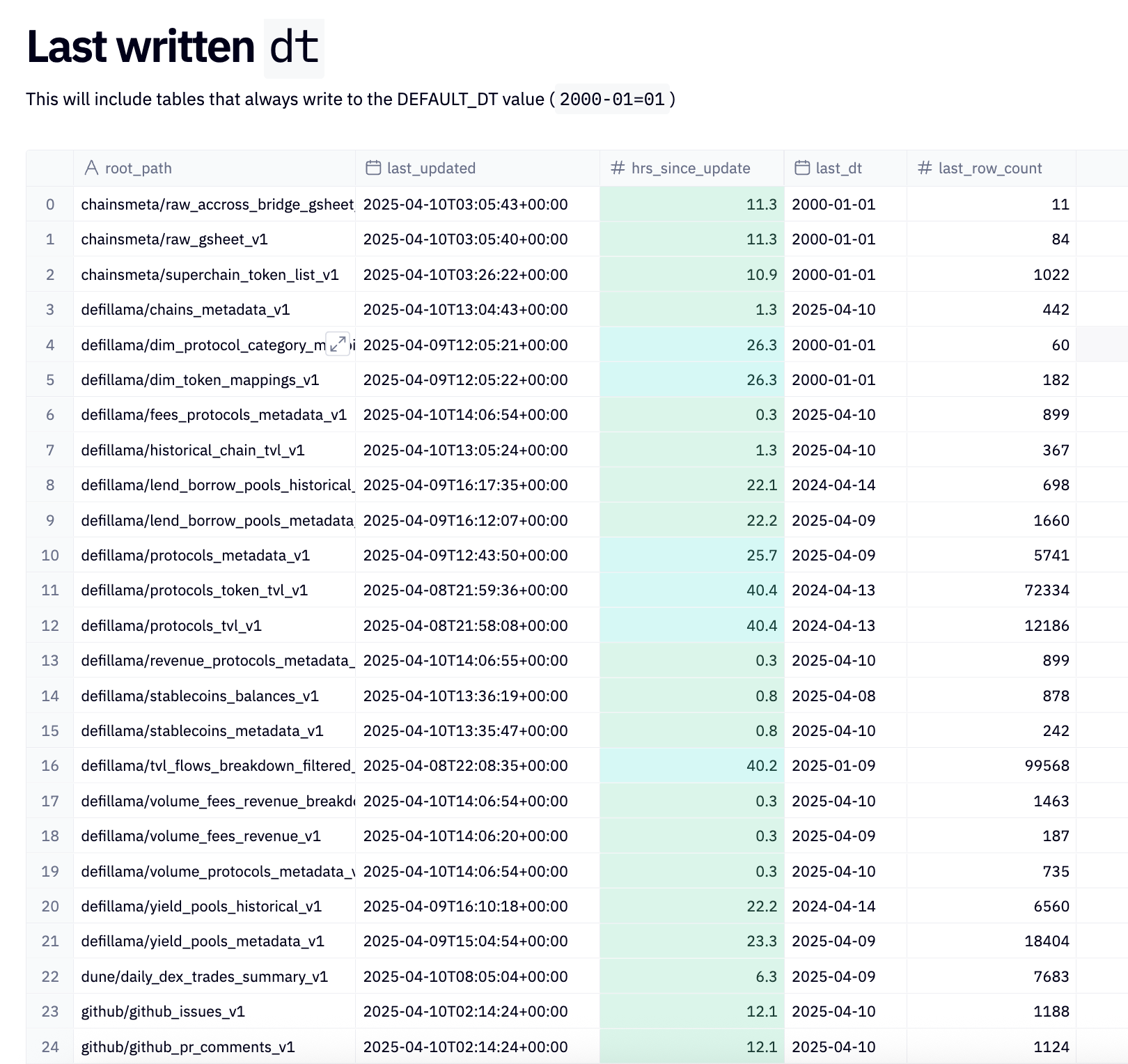
Like for everything else in our data platform we use markers to monitor DailyDataset ingestion.
There is one marker per root_path and dt combination. This allows us to keep an eye of new
data arriving in time for each table and raise alerts on our go/pipeline Hex dashboard when
things are delayed. The marker metadata includes the row count ingested, so we can included
that in the monitoring dashboard as well, right along side the number of hours since last ingested.
Here is a snapshot of part of the dashboard from April 2025:
Advanced use cases#
Some data sources are not easy to implement because of the way in which data is exposed by third-party systems. API calls may be error prone and need to be retried. Or APIs may be rate-limited requiring our systems to back off if they get throttled. Some cases may require a lot of transformations to get the data in the tabular form that we want to ingest it as. All of these cases require creative solutions.
If you encounter a challenge try to check the code to see if maybe there is another data source that has a similar problem that you can borrow some code from.
When to use ClickHouseData instead#
There is also the issue of recovering from transient failures. The DailyDataset pattern requires
you to know all of the data for a single dt at once. If that is a lot of data there may be
cases where you do a lot of work (call many endpoints) and something failing in the middle causes
the job to crash. All the progress made is now lost.
Ingesting data from defillama and ingesting token metadata (totalSupply, etc.) for ERC-20 tokens
are two ingestion use cases that have presented us with that all-or-nothing challenge we encounter
with DailyDataset.
For both of these cases the solution we ended up implementing leverages ClickHouse. We write the
data for a given root_path and dt in a buffer ClickHouse table. If the data pull fails halfway
through the next time it kicks off we can look at the buffer table to see what we were able to
complete on the last run and we resume from there. Once we are done we go ahead and write the
entire dt data to GCS.
This solution works well, but it begs the question: If ClickHouse can offer better facilities for partial progress and incremental data ingestion why don’t we just use ClickHouse as the final destination (instead of as a buffer on the way to GCS)?
The answer is, for some processes (looking at you Defillama), we still need the data in GCS because our reporting logic lives in BigQuery, so we are not ready to move entirely to ClickHouse.
That said, after realizing how convenient ClickHouse ReplacingMergeTree tables are for ingesting
data we decided to provide better support for that pattern, which is what led to the creation of
the ClickHouseData ingestion pattern which we go over in the next section.